SigLIP 2 So400M
ViT-So400M/16-512

CVPR 2026
TL;DR
UniRefiner identifies any token that fails to preserve location-aligned semantics as spurious, then teaches pre-trained ViTs to preserve regular image tokens while pushing spurious responses into boundary registers, enabling lightweight post-hoc refinement of even 8B-scale models within roughly 30 minutes.
PCA dynamics throughout the refining process, comparing frozen vanilla features against UniRefiner under the same rendering setup.











Preliminary
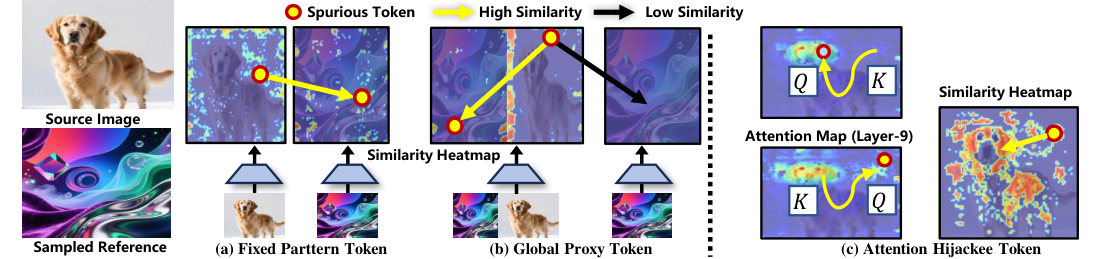
UniRefiner starts from a simple view: for dense prediction, any token that no longer preserves location-aligned semantics should be treated as spurious.
Tokens that remain similar across unrelated images instead of reflecting local visual content.
Tokens that drift toward scene-level context and stop encoding the semantics of their own spatial position.
Tokens that are overwritten by stronger neighbors through attention flow and lose their own spatial identity.
Method
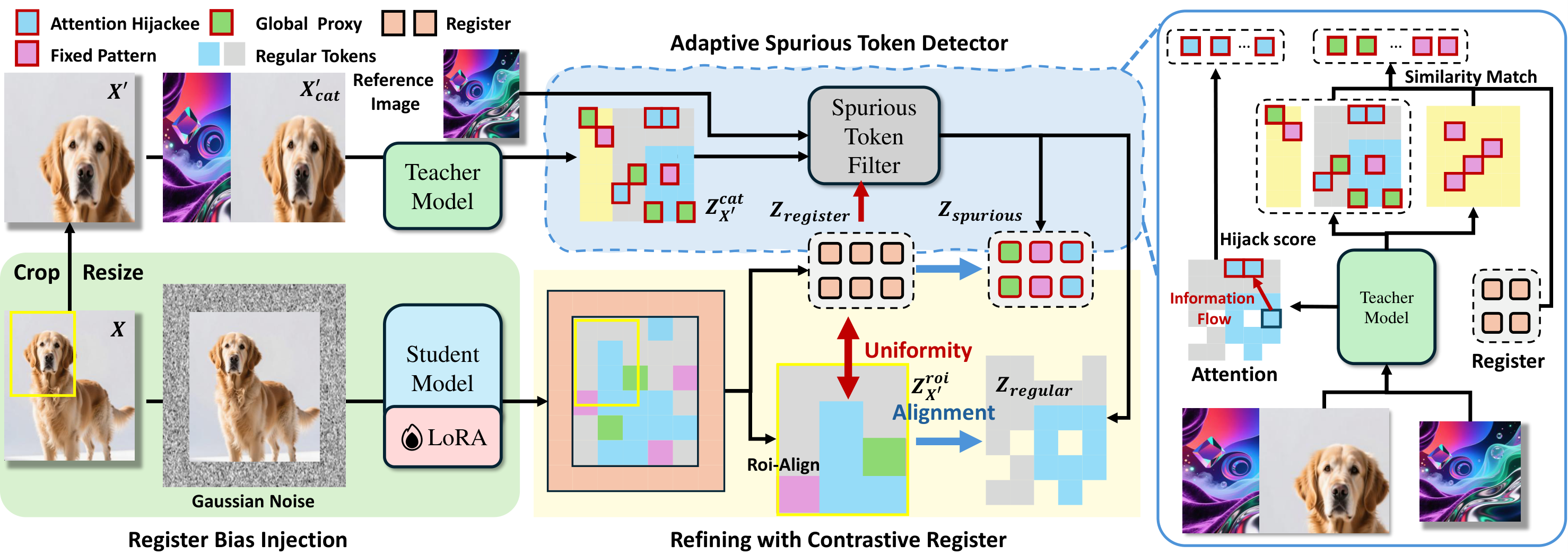
Spurious token filtering. A frozen teacher branch separates regular and spurious tokens using similarity cues, attention flow, and register feedback.
Contrastive register distillation. Student image tokens align to filtered regular tokens, while boundary registers align to detected spurious tokens.
Adaptive refinement. As training progresses, learned registers become stronger spurious detectors and improve the next round of filtering.
Experiment
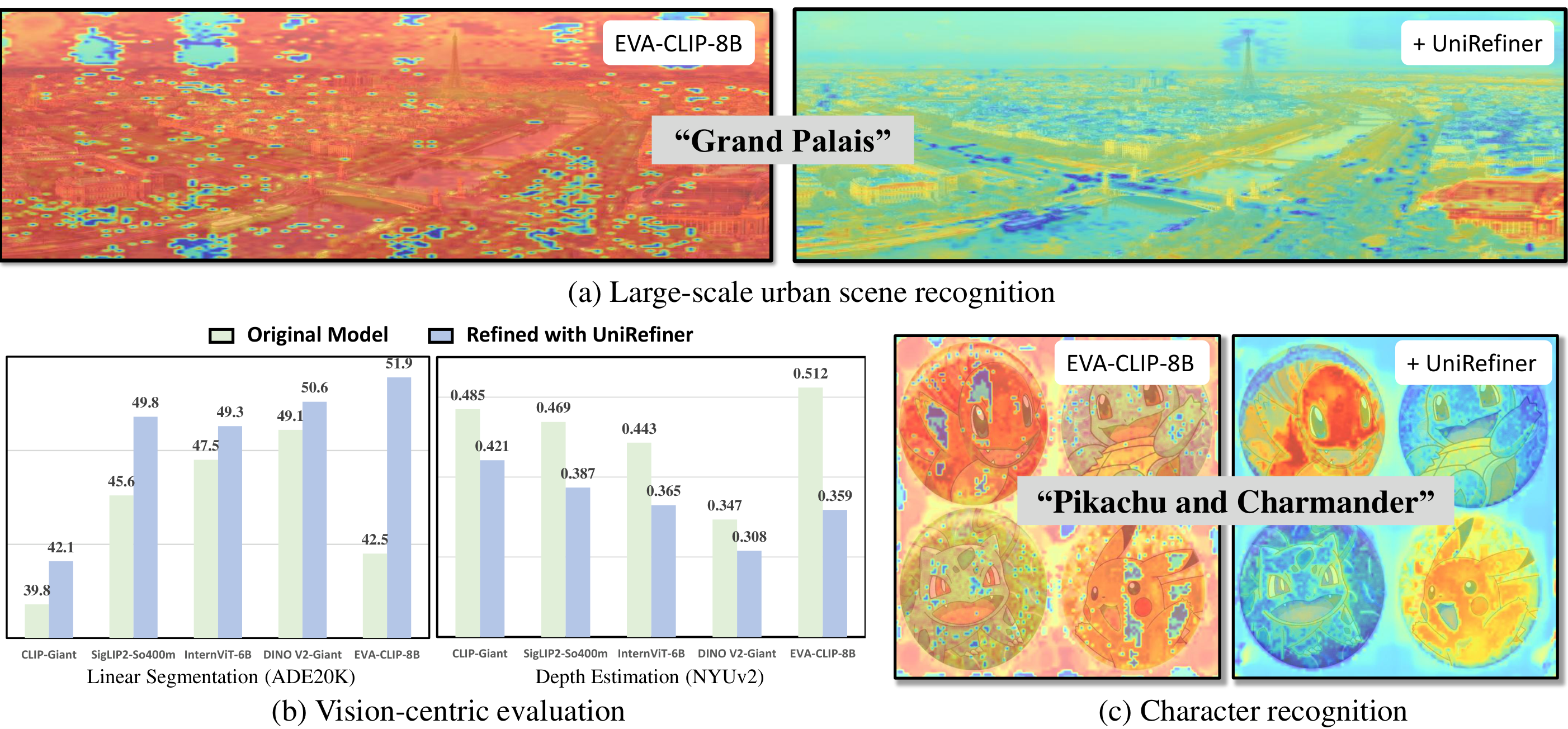
UniRefiner significantly improves dense prediction performance on both visual-centric and vision-language backbones. For the full set of quantitative and qualitative results, please refer to the paper.
Citation
@article{qiu2026unirefiner,
title={UniRefiner: Teaching Pre-trained ViTs to Self-Dispose Dross via Contrastive Register},
author={Qiu, Congpei and Hu, Zhaoyu and Ke, Wei and Tian, Zhuotao and Wu, Yanhao and Zhang, Tong},
journal={arXiv preprint arXiv:2605.19622},
year={2026},
eprint={2605.19622},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.19622}
}